EDUBERROCAL.NET
AI: Crawl, Walk, Run
11-May-2024
It is not surprising to anyone that AI is the new thing in tech. Like anything new, FOMO energy is on full display. I have seen all kinds of jokes about this phenomenon. My favorite one is a meme with a list of the fastest things on earth, with "people becoming experts in AI" as the winner.

Laughing about this, and more importantly, ourselves, is healthy. So, let's make sure we don't take ourselves too seriously. Here is another one:
Now, finding myself at a crossroads in my career, I need to jump into this train. In any case, AI is cool and can solve big and exciting problems for humanity. There is a dark side, too, but I won't get to that here. I will also not talk about AI winters and summers, the true meaning of intelligence, or if the "I" in AI is really that intelligent. I have my thoughts that I will write out in a future article.
What I want to do today is talk about my journey. As with all journeys, they have to have a start. Disclaimer: I have some experience in data analysis and Machine Learning (ML), so AI is familiar to me. The part where I needed more experience was in the world of neural networks. As it turns out, neural networks are the backbone of the present AI revolution. So, let's get started!
The place where I started is an excellent course on Udemy called Artificial Intelligence A-Z 2024: Build 7 AI + LLM & ChatGPT. In terms of algorithms, they cover Q-learning, Asynchronous Advantage Actor Critic (A3C), Proximal Policy Optimization (PPO), Soft Actor Critic (SAC), and Large Language Models (LLMs). It also has two annexes covering the basics of Artificial Neural Networks (ANNs), which are very good.
So far, I have only done Q-learning (around half the course), but it is already sparking my imagination. Q-learning is exciting and my first encounter with Reinforcement Learning (RL). In RL, instead of having a bunch of training samples that you capture and batch together to feed to the training algorithm (like in classic ML), the training is done "on the fly" using feedback (reinforcement) from the environment. Think of a robot that has to learn how to walk from point A to point B in an environment with dangers like pits and obstacles like objects or columns where the robot can get stuck. The environment provides feedback as a reward score, usually negative in the places where the robot should not go and positive in the areas where the robot should go. The environment only provides limited feedback (otherwise, tagging the whole environment would be prohibitively expensive), and it is up to the algorithm to discover the "Q values" associated with other locations (states) so future robots can walk safely from A to B.

The robot itself does the training, performing walks. These walks have some randomness added to them to avoid climbing "local maximums" that can prevent us from learning better routes, such as shorter ones.
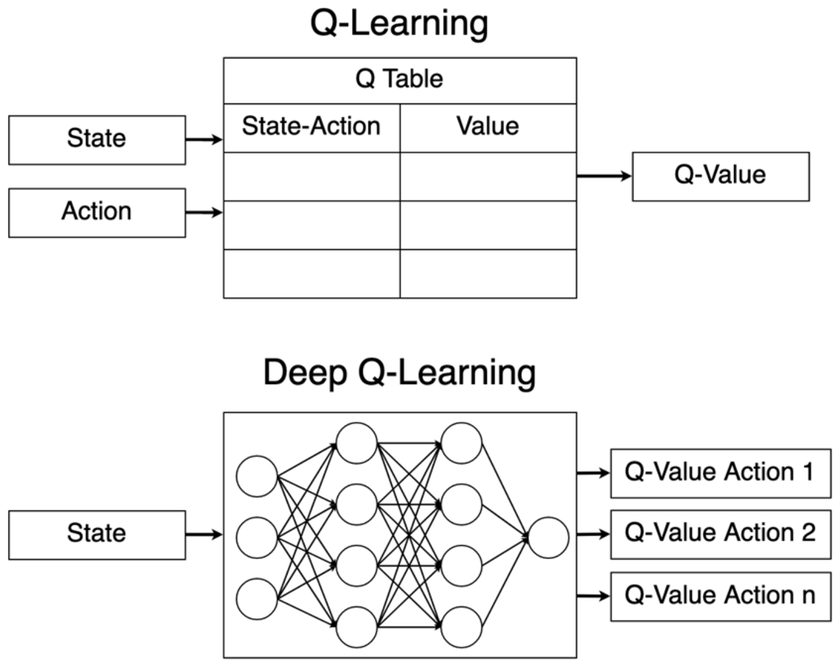
In theory, ANNs are not needed for Q-learning. However, depending on how you design your algorithm, the table to store all the values for each state-action can become quite large. Given that a Q table has a lot of superfluous information, an ANN can remediate this problem by finding the patterns in the data for us! Here comes Deep Q-learning:
(image source)
One way to showcase Deep Q-learning is by playing old Atari games :-). The first programming exercise, using PyTorch, is to create an AI that can learn to land a lunar module safely on the moon's surface in the desired location. Gymnasium, an API standard for reinforcement learning with a diverse collection of reference environments, provides "the game." You can find it here.
The following video shows how my AI landed the lunar module after using the previous 479 landings (in RL parlance, episodes) for training purposes:
Not bad.
The code in Python was surprisingly short and elegant. I was genuinely impressed by PyTorch. For example, the class to create the architecture of the neural network is as simple as this:
class Network(torch.nn.Module):
def __init__(self, state_size, action_size, seed = 42) -> None:
super(Network, self).__init__()
self.seed = torch.manual_seed(seed)
self.fc1 = torch.nn.Linear(state_size, 64)
self.fc2 = torch.nn.Linear(64, 64) # 2 layers!
self.fc3 = torch.nn.Linear(64, action_size)
def forward(self, state):
x = self.fc1(state)
x = torch.nn.functional.relu(x)
x = self.fc2(x)
x = torch.nn.functional.relu(x)
return self.fc3(x)
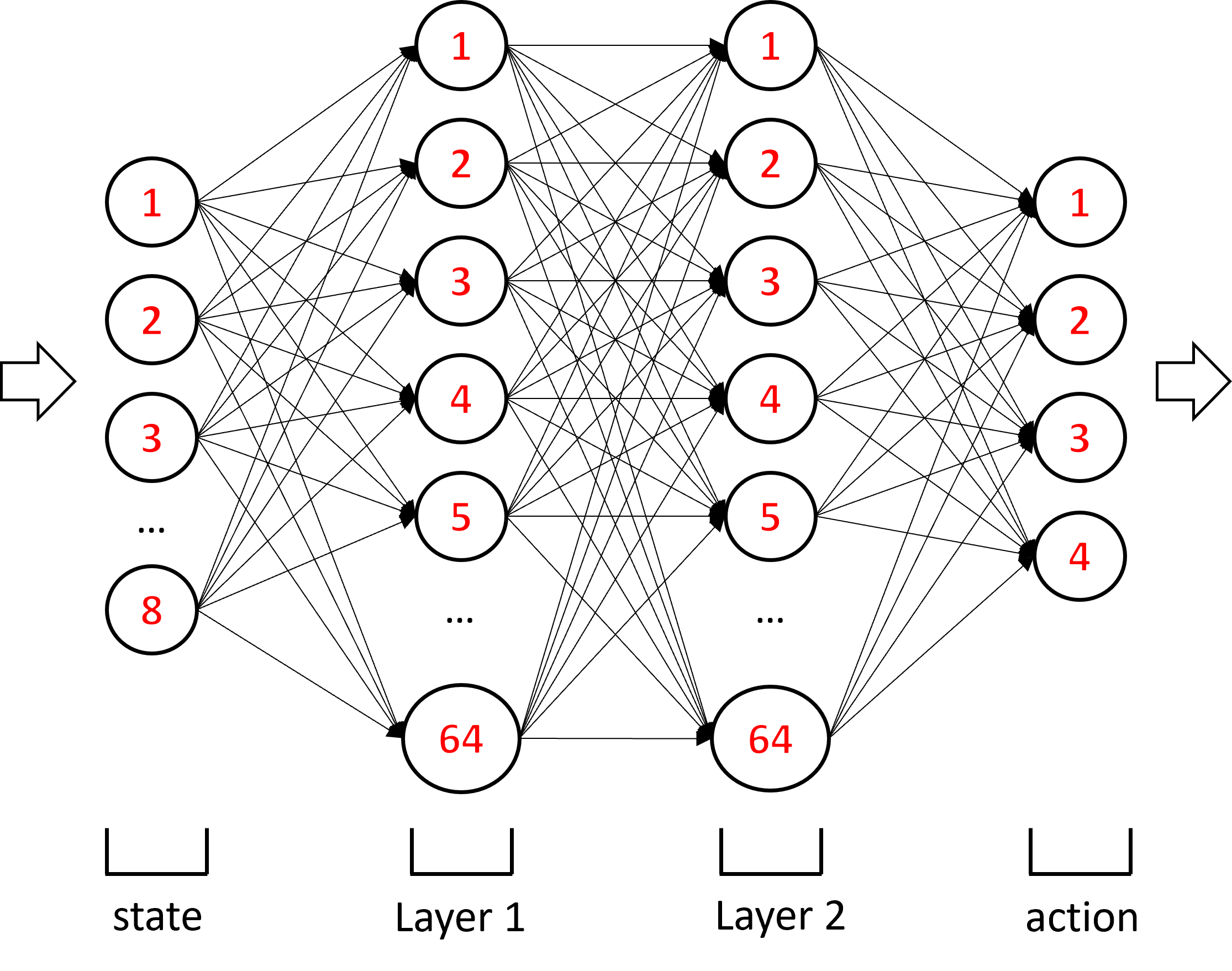
As you can see, the architecture of the network in the __init()__ function is defined with 3 lines of code. In this case, the exercise gave me the number of neurons in each of the two layers, 64. Apparently, 64 was reached after some experimentation and it works well for this game. The class also has a forward() function, which calculates the network output given a particular input (state). The activation function used here, relu(), is the rectifier linear unit, which is equal to relu(x) = max(0,x). The neural network looks like this:
Another part of the code I want to comment is the training loop, which shows the high-level mechanics involved in training our AI agent:
number_episodes = 2000 # max num episodes over which we want to train out agent
maximum_number_timesteps_per_episode = 1000
epsilon_starting_value = 1.0
epsilon_ending_value = 0.01 # we decay epsilon over time
epsilon_decay_value = 0.995
epsilon = epsilon_starting_value
scores_on_100_episodes = deque(maxlen = 100)
for episode in range(1, number_episodes + 1):
# reset state
state, _ = env.reset() # env is where the 'real' action takes place
# init the score
score = 0
for t in range(maximum_number_timesteps_per_episode): # learning loop
# action selected
action = agent.act(state, epsilon)
# we make a move, we are in a new state
next_state, reward, done, _, _ = env.step(action) # done is a bool: are we done?
# We use the step method, that includes the learn method with backpropagation
agent.step(state, action, reward, next_state, done)
#
state = next_state
score += reward
if done:
break
# episode finished
scores_on_100_episodes.append(score)
epsilon = max(epsilon_ending_value, epsilon_decay_value * epsilon)
if np.mean(scores_on_100_episodes) >= 200.0: # condition to win
torch.save(agent.local_qnetwork.state_dict(), 'checkpoint.pth') # saving the solved one!
break # we are done
You can find the complete code here if you want to check it out.
If we look at the parameters, we see that we will only iterate over 2000 episodes in total. Nevertheless, we unlikely need 2000 episodes before reaching a solution. That value ensures the loop does not go on forever if we do something wrong. Likewise, each episode will go for only 1000 timesteps in total. Again, an episode may need fewer timesteps if it reaches the ground (winning or not) before that.
The variable epsilon introduces randomness. We start with a high value of 1.0, meaning that, at the beginning, we will mostly move at random. As time progresses (i.e., after each episode) we decrease (decay) the value of epsilon so we shift from picking moves at random to trusting our neural network more and more. This is key, as the network is useless at the beginning and picking moves at random allows as to explore the space better and learn more. But as time progresses, we want to trust our learned network more and more, so we "refine" our skills rather than move at random. This is similar as to how a toddler learns to walk. Initially, toddlers fall because their actions with their body parts are random. But as they start to get rewards from the environment (falling hurts; not falling gets smiles from mom), the walks become more and more stable as movements that do not work get discarded. As they learn, however, toddlers may still need some randomness. For example, they may know how not to fall when standing still but not how to move forward.
The training progresses in two loops. The first one goes over each episode. It starts resetting the environment (meaning resetting the game). The second loop covers the movement (timesteps) in a single episode. In there, we first calculate what action to take given our current state (state is the position of the lunar module) and epsilon with agent.act() (which is a method we have to code). Given the action we are performing, we then calculate the next state and its reward. For that, we call the environment (the game) again, with env.step(). That function also gives a Boolean variable named "done," which tells us if the episode is done. After that, we call the method agent.step() (a method we have to code) to perform the actual learning. And that is it. We end the loop when done is true.
The game is "won" when we reach an average score over the previous 100 episodes of 200 points. This is game dependent. Each episode gets a score, which is the summation of all the rewards from all the timesteps. The reward is described on the game page and is the following:
For each step, the reward:
- is increased/decreased the closer/further the lander is to the landing pad.
- is increased/decreased the slower/faster the lander is moving.
- is decreased the more the lander is tilted (angle not horizontal).
- is increased by 10 points for each leg that is in contact with the ground.
- is decreased by 0.03 points each frame a side engine is firing.
- is decreased by 0.3 points each frame the main engine is firing.
- The episode receive an additional reward of -100 or +100 points for crashing or landing safely respectively.
- An episode is considered a solution if it scores at least 200 points.
Our reward increases as our lunar module gets closer to the landing pad. This favors movements that correct the module to point to where it is supposed to land. We get another reward for each leg touching the ground when we land. We get penalized if the lander goes too fast, if it tilts (I guess the astronauts can get dizzy), and every time we have to fire the engines to correct course (the more you fire them, the more fuel you waste). Finally, we received a big reward or penalty, depending on whether we landed safely or we chrased.
Well, I will end it here today. I can say now that I have created my first AI! I am safely crawling... and hope to walk and run soon.
