EDUBERROCAL.NET
Firewall Hole Punching
30-September-2024
I have been working on some ideas recently, and the need for a peer-to-peer (P2P) architectural design came up. If you, like me, grew up with the wild internet of the late 1990s/early 2000s, you will surely remember P2P networks and their mythical programs such as eMule. P2P networks still exist nowadays, but they have somehow faded to the background thanks to the advancement of high-bandwidth internet at homes, streaming services, cloud computing, and sharing through social media platforms.
I remember that world with fondness. Not so much for what I could access through P2P networks (out of which, I must admit, not all was copyleft), but because they had a feeling of genuine internet. Pure decentralization. Out of a 1980s world of mainframes and thin clients that weren't much more than a keyboard, a screen, and a modem, we suddenly had desktop machines powerful enough to simultaneously be both servers and clients. If you think about it, P2P networks are the closest to the original philosophy of the internet (former ARPANET) you can get. The more decentralized a network is, the harder it is to disrupt it.
Fast forward to 2024, and suddenly (well, not suddenly, but gradually since 2010 or so), our machines are back to being just thin clients connected to "mainframes." Clients are now browsers (the ultimate application platform), and mainframes are now powerful cloud services. XKCD summarized it well with a joke mocking the classical Apple commercials:

The physical wiring of the internet may be decentralized, but our digital life--including "our" data as well--is not. And yes, I quoted "our" because we have reached a point where we don't even own what is ours. All our digital life is routed and stored on a few machines in a few data centers worldwide. One may think that the typical 2-3x replication on different locations is robust enough, but that is still a centralized architecture. Yes, our cloud services may be OK in 99.999% of the cases (as the classical telephone networks were), but when things go south, destroying 100 data centers or so may not be as difficult as some people think. Not to mention data privacy and having control of what is done with our data, but I won't go there...
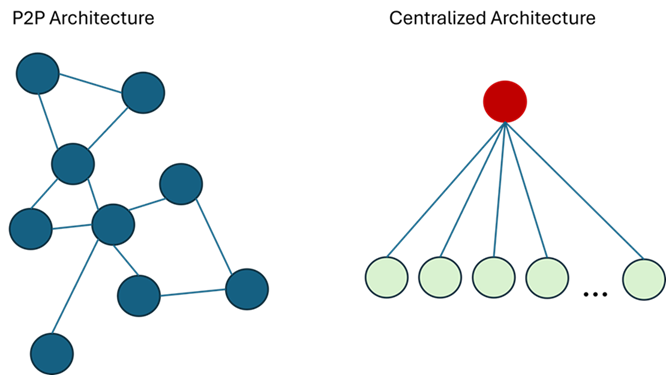
So I was having these thoughts when I remembered that one of the reasons we have the internet we do is because of ease of use (the other is that centralized services are easier to monetize, and hence, the whole industry is behind those). Configuring a system to be used as part of a P2P network still requires some basic knowledge of networking, and that is sometimes enough to prevent mass adoption.
One of the issues with P2P networks is that the network nodes must be able to work as servers. Configuring a server implies, at the very minimum, opening ports on your Operating System (OS) firewall (and maybe antivirus too). In reality, that is not enough. No home computer today connects to the internet using a public IP directly. Instead, one public IP is assigned to the whole home network, and the router uses Network Address Translation (NAT) to route packages to the proper computer, which uses a private IP. Given this, users need to configure their home routers to be able to do port forwarding.
One of the solutions to this problem is firewall hole punching. This solution, however, adds some centralization to the P2P network. Because of this, for example, eMule penalized users who didn't have their ports opened, as this added expensive CPU cycles to their servers (and they weren't charging for the service). Nevertheless, with the increase in networking speeds and server capabilities, CPU cycles have gone down in price significantly. And, thanks to cloud computing, it is as easy as ever to deploy a "thin server" in the cloud quickly. You read it correctly, thin server. I think cloud computing is a revolutionary invention, and I don't think one should be a purist. If we want to go back to having more P2P services, a good approach could be to make then pseudo-P2P, having the best of both worlds: (1) privacy and de-centralization using P2P, and (2) easy of use and coordination, having some centralized components.
Code Sample
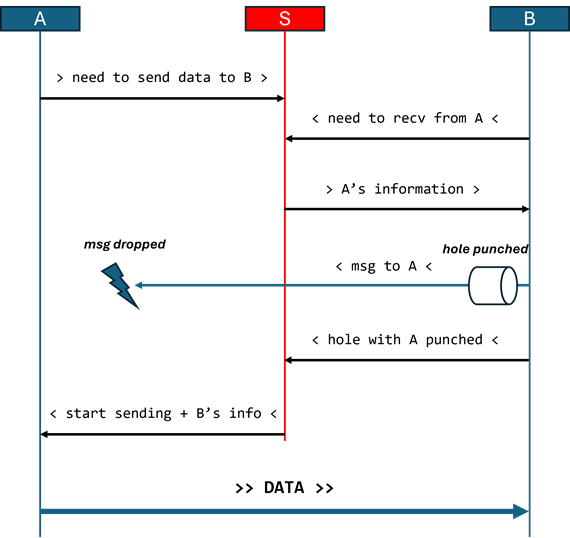
I wanted to test this and see it working with my eyes. The mechanism of hole punching is quite simple. Let's say A wants to send data to B directly. To do that, A sends a message to S (the server) specifying that it wants to send data to B as well as its own UDP port (A should have created, before contacting S, its own UDP socket and bound it to an open port). Following this, B sends a message to S specifying that it wants to receive data from A as well as its own UDP port (like A, B should have created its own UDP socket and bound it to an open port). The server S will respond to B with A's information: UDP port and maybe IP if A's IP was unknown to B.
After this point, B sends a UDP package to A to punch the hole in the firewall (this is when the "magic" happens). The message will never reach A, but that is not the point. The point is for B's firewall to "remember" A. Given that, in the eyes of the firewall, B initiated the communication with A, any package that comes back from A will be allowed to go through. This works because, otherwise, the internet wouldn't work. For example, to load a page from a server on the internet, a browser first has to contact the server (communication direction is out). After that, the server has to be able to send the page information back to the user (communication direction is in). I am simplifying, of course, but the point is the same.
Finally, B will signal to S that the hole was punched and S will signal to A that it can start transferring data to B. Along with this last message, S will also send B's information to A: UDP port and maybe IP if B's IP was unknown to A.
The following is the code for the server logic (you can find the full proof-of-concept code here):
#include "tcp_conn.h"
#include "proto.h"
#include <stdio.h>
#include <errno.h>
#include <string.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
int port;
tcp_server_t* server;
int conn;
int conn1 = -1;
int conn2 = -1;
proto_t msg;
proto_t msg1;
proto_t msg2;
/** arguments */
if (argc < 2) {
fprintf(stderr, "USE: %s <PORT>\n", argv[0]);
return -1;
}
port = atoi(argv[1]);
if (tcp_conn_create_server(port, 5, &server) < 0) {
return -1;
}
fprintf(stdout, "server created\n");
/** accepting new connections */
while (1) {
if (tcp_conn_new_connection(server, &conn) < 0) {
return -1;
}
fprintf(stdout, "new connection from %s\n",
server->active_conns[conn].ipv4);
if (tcp_conn_recv_msg(server,
conn,
(void *)&msg,
sizeof(proto_t)) < 0) {
return -1;
}
fprintf(stdout, "received command %d\n", msg.cmd);
if (msg.cmd == 1) { // sender
if (conn1 >= 0) {
fprintf(stdout, "recevied command 1 twice! destroying ");
fprintf(stdout, "connection...\n");
if (tcp_conn_destroy_connection(server, conn) < 0) {
return -1;
}
continue;
}
conn1 = conn;
msg1 = msg;
strcpy(msg1.ipv4, server->active_conns[conn].ipv4);
} else if (msg.cmd == 2) { // receiver
if (conn2 >= 0) {
fprintf(stdout, "recevied command 2 twice! destroying ");
fprintf(stdout, "connection...\n");
if (tcp_conn_destroy_connection(server, conn) < 0) {
return -1;
}
continue;
}
conn2 = conn;
msg2 = msg;
strcpy(msg2.ipv4, server->active_conns[conn].ipv4);
}
if (conn1 >=0 && conn2 >= 0) {
/** send sender info to receiver */
if (tcp_conn_send_msg(server,
conn2,
(void *)&msg1,
sizeof(proto_t)) < 0) {
return -1;
}
/** wait for receiver permission for transfer start */
if (tcp_conn_recv_msg(server,
conn2,
(void *)&msg,
sizeof(proto_t)) < 0) {
return -1;
}
/** send the receiver info to sender */
if (tcp_conn_send_msg(server,
conn1,
(void *)&msg2,
sizeof(proto_t)) < 0) {
return -1;
}
/** destroy connections */
if (tcp_conn_destroy_connection(server, conn1) < 0) {
return -1;
}
if (tcp_conn_destroy_connection(server, conn2) < 0) {
return -1;
}
conn1 = -1;
conn2 = -1;
}
}
// we never really reach this part of the code
return 0;
}
All the server does is waiting for two clients to connect: client A or sender (command 1), and client B or receiver (command 2). After both commands have arrived, the server sends A's info to B and waits for its signal that the hole is punched. After that, it sends B's info to A, which also signals to A that it can now transfer data to B directly.
Realize that communication from clients to the server is done using TCP, but transfer between clients is done using UDP.
The following is the code for the POC client logic:
#include "tcp_conn.h"
#include "udp.h"
#include "proto.h"
#include <stdio.h>
#include <errno.h>
#include <string.h>
#include <stdlib.h>
int main (int argc, char *argv[])
{
char* serverIP;
int serverPort;
int cmd;
tcp_client_t* tcp_client;
udp_t* udp;
proto_t msg;
proto_t msg1;
if (argc < 4)
{
fprintf(stderr, "USE: %s <SERVER_IP_ADDR> <SERVER_PORT> <CMD>\n",
argv[0]);
return -1;
}
serverIP = argv[1];
serverPort = (uint16_t) atoi(argv[2]);
cmd = (int) atoi(argv[3]);
if (cmd < 1 || cmd > 2) {
fprintf(stderr, "Error, wrong command -> %d\n", cmd);
return -1;
}
if (tcp_conn_create_client(&tcp_client) < 0) {
return -1;
}
if (udp_create(1234, &udp) < 0) {
return -1;
}
if (tcp_conn_connecto_server(tcp_client, serverIP, serverPort) < 0) {
return -1;
}
/** send data to server with command and UDP port */
msg.cmd = cmd;
msg.port = udp->port;
if (tcp_conn_client_send_msg(tcp_client, (void *)&msg, sizeof(msg)) < 0) {
return -1;
}
/** receive data from server again (info from other client) */
if (tcp_conn_client_recv_msg(tcp_client,
(void *)&msg1,
sizeof(msg1)) < 0) {
return -1;
}
if (cmd == 1) {
/** Send UDP package through firewall hole !! */
strcpy(msg.msg, "Hello World!");
fprintf(stdout, "sending UDP with message = %s\n", msg.msg);
if (udp_send_msg(udp,
msg1.ipv4,
msg1.port,
(void *)&msg,
sizeof(msg)) < 0) {
return -1;
}
} else { /* cmd == 2 */
/** create firewall hole */
if (udp_send_msg(udp,
msg1.ipv4,
msg1.port,
(void *)&msg,
sizeof(msg)) < 0) {
return -1;
}
/** Let server know that the hole was punched */
if (tcp_conn_client_send_msg(tcp_client,
(void *)&msg,
sizeof(msg)) < 0) {
}
/** receive UDP package */
if (udp_recv_msg(udp, (void *)&msg1, sizeof(msg1)) < 0) {
return -1;
}
fprintf(stdout, "(UDP) received !!!!\n");
fprintf(stdout, "message = %s\n", msg1.msg);
}
if (tcp_conn_destroy_client(&tcp_client) < 0) {
return -1;
}
if (udp_destroy(&udp) < 0) {
return -1;
}
return 0;
}
The client connects to the server and sends its info to it. Then, the client receives the info for the other peer (either to receive or to send) from the server. If command 1 is chosen, the client (in this case, the sender) sends the message--"Hello World!"--directly to the other client (the receiver). Realize that client 1 will block on the tcp_conn_client_recv_msg() function until client 2 is done punching the hole; it is waiting for the server to let it continue.
Conversely, if command 2 is chosen, the client will send a UDP package to the client 1 to punch the hole. This message won't block because it is UDP, so it doesn't require acknowledgment. After that, it will let the server know that the hole was punched and wait for client 1's UDP message.
The End
That is it! I have always known about this technique, but it was fun to see it work. I tested this using two cloud virtual machines (VMs) and my home computer. My home computer was the server; the two clients ran on the cloud VMs. To make sure a hole was punched, I left all ports closed on the cloud VMs except for SSH.
